







AI

Neural implants
Nick Flaherty examines the issues around training neural networks in uncrewed systems
Machine learning (ML) and AI are used in many different ways and in different parts of uncrewed systems for a range of functions to boost their performance. For example, AI is used extensively for applications based on image processing. These vary tremendously, from providing an alternative to airborne navigation to monitoring infrastructure.
AI can be considered the overarching term for ML for decision-making, particularly with the ability to learn, while ML itself is the ability of systems to make decisions on data without specific instructions.

At the heart of this is the neural network, which is inspired by biological networks that have layers of interconnected nodes, or neurons. Each neuron in one layer is connected to every neuron in the next layer via a filter that uses a weighting system to determine the probability of a connection to a node in the next layer. Networks with several layers are called deep neural networks (DNNs), and for image processing the most common type is the convolutional neural network (CNN).
There are other types of network, for natural language processing for voice control or signal chain processing for predictive maintenance (as detailed in UST 45, August/September 2022). Neuromorphic networks, also known as spiking neural networks, are also increasingly popular for low-power systems such as UAVs (see sidebar) that need image recognition, as these are only active when there is a change in the signal.

In practice, using a DNN for image analysis breaks down into two areas: training and inference.
For supervised learning, a network is trained with samples from an image sensor as a stream of pixels or from a Lidar or radar sensor where the outputs are a point cloud. The key is that these inputs are tagged, highlighting any areas of interest. These areas of interest can be images of pedestrians, other vehicles, animals, road markings or even wind turbine blades.
This tagged data is run through the network during the training process, and the weights are adjusted to achieve the same output as the input for the tagged data.
That creates a framework of weights that can be used to identify similar images when they are presented, and this is the process of inference. The greater the number of sample images provided, the higher the probability of accurate recognition. These weights can be in a 32-bit floating-point format (FP32), 16-bit (FP16) or 8-bit (FP8).

The processes of reducing the resolution of these weights so that they can be useful for an uncrewed system is called quantisation. This reduces the size of the framework, requiring less memory for inference and allowing faster operation. However, it can lead to less accurate results, which for an application such as driverless cars is critical. The tools for working with the frameworks are key for the safety of the end system.
Another issue is that the tagging process is not very scalable, as people have to tag the structures in millions of images or point clouds.
An alternative approach is to use ‘synthetic data’ generated by a simulation. Synthetic data tools run a simulation of vehicles in an environment to provide the data already tagged for training the neural network. That avoids having to create images for every kind of environment, whether urban, rural or motorway driving for a driverless car or the images a UAV would see from the air for navigation.
The tools can also create specific scenarios that might not occur very often, for example if one vehicle obscures another. These rare ‘edge cases’ and ‘corner cases’ can be created by the simulation tools.
This training is performed increasingly by supercomputers using custom processor chips or off-the-shelf graphics processor units (GPUs), taking millions of images as their input to build a framework of weights. These make use of the multiply accumulate (MAC) units in GPUs that were previously used for graphics applications. There are also custom chips that increase the number of MACs to boost the training performance, but this requires a different chip and interconnect architecture.
Other tools can then take the frameworks and optimise them for the inference engines. The engines have to be optimised for lower power consumption, to run in vehicles, ships or even UAVs. While PCs can run the frameworks, GPUs are better suited to the calculations, and there are custom designs that are optimised for the workloads required by specific frameworks.
Another issue is unsupervised learning using the data acquired using the camera, Lidar and radar feeds in a vehicle.
While this could be used to improve the quality of the framework by adding more data, it needs some kind of tagging, This could be performed locally, but that takes a lot of processing power. The data can also be sent to the cloud for processing in the supercomputer, but that can take a lot of bandwidth.
To avoid this problem, the data can be stored on the vehicle and downloaded at another time, although that is not a scalable solution and is only used during development. There are tools that select suitable frames from the feed and send these back to a central server to provide more training data.
These tools already run on millions of vehicles using ADAS collision detection systems, building up more data for training autonomous systems.

There is also a safety aspect. For a driverless car, for example, the framework is part of the safety case, so it is certified in a particular form. If that changes with more training then extra safety certification can be required.
There is also an issue called sparsity. Many of the images collected have large areas that are not relevant but still have associated weights. That creates huge frameworks of gigabytes of data where most of the data is irrelevant. Being able to filter out that irrelevant data during training is a key way to make the frameworks smaller and more efficient, but it can require more complex training hardware.
Wind turbine inspection
The task of inspecting and maintaining wind turbines, both onshore and offshore, is becoming increasingly challenging, and there is a clear need for faster, safer inspections that produce high-quality data in order to pursue preventative maintenance and reduce the requirement for technicians to attend turbines.
ML techniques have been used specifically to inspect wind turbines. The basic principle is the complete automation of the inspection process. In one application a tablet device allows an operator to command a UAV to take off to collect high-quality data of the whole turbine in less than 20 minutes, autonomously.
After landing, a cloud-based system uses an ML framework to process the images to detect any damage. That allows engineers to view the results of an inspection within 48 hours rather than the traditional time of around 2 weeks.
The input data is collected using Lidar and a camera as well as an inertial measurement unit (IMU). The data is compared against a simplified 3D model of the structure being inspected, allowing the location of the asset to be identified and providing the optimal positioning of the system.
The ML framework is built in PyTorch, which is open source and helps develop rapid prototypes and ultimately take the 3D models through to production, deploying object detection models. Implementing processes such as data augmentation, model tracking, performance monitoring and model retraining is easy to navigate.
The framework is trained and retrained locally using a dedicated ML workstation, which uses commercial RTX graphics cards using a mainstream GPU. The main limitation is the GPU’s memory, with memory requirements being a challenge owing to the size of the raw data at 45 MP.

Research has shown this combination of UAVs and AI can be 14% more accurate in detecting faults in wind turbines when compared with human experts carrying out the same inspections. Using AI also reduces the data review time by 27% to achieve that 2-day turnaround.
The framework is constantly being updated to improve the performance of the model and the accuracy of the results. For example, the model is being enhanced to make accurate predictions about blade damage and make generalisations about new situations and new types of images.
The AI can be extended to other types of infrastructure, such as solar farms. The positioning system would be combined with an ML framework trained on images of solar panels to identify cracks in the panels and supports.
Wind turbine simulation
One simulator was originally developed as a cross-platform open source system that combines the Unreal and Unity 3D display engines with popular flight controllers such as PX4 and ArduPilot, and hardware-in-loop with PX4 for physically and visually realistic simulations.
Using cloud computing, ML models can run through millions of flights in seconds, learning how to react to a wide range of variables. This synthetic data can be used to look at how a UAV would fly in rain, sleet or snow and how strong winds or high temperatures would affect battery life.
Developers can use pre-trained AI building blocks, including models for detecting and avoiding obstacles, and executing precision landings, as well as simulations of weather, physics and the sensors used on a UAV.
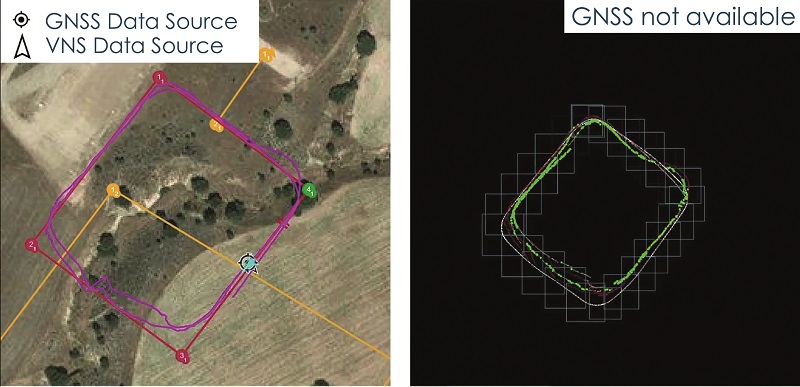
CNN frameworks are also being used for visual navigation on a UAV during a mission. A camera on the UAV can capture images of the ground, which can be matched against a framework running on a microcontroller.

This can identify structures on the ground that can be matched to the structures on a map to provide information about the location. That can be combined with data from the IMU and GNSS navigation to feed into the autopilot. Using the image data and AI inference during the flight can provide more accuracy for the positioning if there are issues with the GNSS.

Radar
AI is also used to improve the performance of radar sensors in autonomous vehicles. It can be used to reduce the noise in the point cloud, providing more reliable data on the position and speed of objects.
Radar and Lidar have different challenges to visual images for the AI framework. Because the input is a point cloud rather than a more dense array of pixels, even the smallest changes to the incoming data during inference are enough for the output to collapse. That means objects are not detected or are detected incorrectly, which would be devastating in the autonomous driving use case.
The framework is therefore trained using noisy data with the desired output values, testing different models to identify the smallest and fastest ones by analysing the memory space and the number of computing operations required per denoising process.
The most efficient models are then compressed by quantisation to reduce the bit widths – that is, the number of bits used to store the model parameters. This produces a framework with an accuracy of 89% using just 8 bits, equivalent to a framework using 32 bits but with only 218 kbytes of memory, a reduction in storage space of 75%.
Hardware
AI accelerators for image processing are now being added to low-power microcontrollers to handle inference with low power consumption for UAVs and AGVs. The latest dynamically reconfigurable processor (DRP-AI) accelerator adds a compiler framework and open source deep-learning compiler. A translator tool converts the framework into code that can run on the DRP-AI.
Framework development tools such as the open source ONNX tool, PyTorch and Tensorflow are used to build up the frameworks, although there are other proprietary tools that are optimised for certain applications, particularly for driverless cars.
One challenge for embedded systems developers who want to implement ML is to keep up with the constantly evolving AI models. Additional tools for the DRP-AI engine allow engineers to expand AI frameworks and models that can be converted into executable formats, allowing them to bring the latest image recognition capabilities to embedded devices using new AI models.

For example, the resolution of image sensors continues to increase – sensors that are 1080 pixels wide are becoming more popular, but some of the most common frameworks have been trained on images that are only 244 pixels wide.
While it is still possible to use these frameworks, more processing has to be performed for scaling, and the accuracy is reduced. It is also less efficient in processing, so more hardware resources are needed, driving up the power consumption and cost.

So there is a constant battle for AI frameworks to keep up with technology development in driverless vehicles.
These frameworks have been developed over the past decade for ADAS systems, which use forward-looking cameras to capture a vehicle in front, the lane markings on the road and any potential obstructions. The ADAS system supports a driver, issuing a warning if the vehicle is veering off the road or triggering the emergency braking system to prevent a collision.

This is a more tightly bound problem than full autonomous operation, so it can make up only a part of the overall solution. ADAS systems also rely on a driver in the vehicle, so have a lower safety requirement. Moving to full autonomy requires much more redundancy in the system design, including in the AI framework.
For a driverless vehicle, the latest AI framework consists of 5 million lines of code to ensure that the system can be certified to the highest level of safety, ASIL-D, as part of the ISO 26262 safety process.
Running this framework requires a high-performance processor to handle the inference, and the next-generation devices will handle 2 TOPS, or 2 million mega-operations per second. Devices with that level of performance will be in production in vehicles in 2025; however, the exact performance requirements depends on the sensor architecture of the vehicle and the mix of image sensors, Lidar and radar.
The development and simulation tools are key, supporting multiple DNNs with the ability to change sensor configurations and positions, and add other road users. For example, the tools can reconstruct a 3D scene from the recorded data and add human and synthetic data, then generate the images needed for training the framework.
The tools can take a video input and 360º scene creation, and extract other cars and people to leave a driveable scene. That allows the focus vehicle and other road users to move through the scene using the laws of physics and test the software stack to scale the testing of edge cases to create a massive number of scenarios.
The tools can also simulate all the other software in the car, including displays and the infotainment system, to test how the data moves around the vehicle using the actual software that will run in the vehicle. This can ensure that data from key components, particularly sensors, is not blocked or delayed by other applications.

However, the evolution of the AI framework development tools from Level 2 and Level 3 ADAS applications to full autonomous operation at Level 4 and Level 5 is pushing for more hardware independence.
That would allow all the investment in the complex development of the framework to be moved from the chips from one manufacturer to another without compromising the performance.
That avoids being locked into a particular software stack and supply chain, and gives the flexibility to use different chips for different vehicle designs, from a budget platform to high-end luxury versions, using the same safety-certified AI framework.
This hardware independence relies on the fact that the underlying processing architecture for most autonomous vehicle applications is based on MAC units.
The MAC units can be connected in different ways with different amounts of memory, but the underlying architecture is similar.
As the workload evolves, so does the AI, and the processing requirement for the AI needs to keep up as the system requirements keep changing. For example, there are older, tested frameworks running on new hardware, new frameworks running on older hardware in existing vehicles and new frameworks running on new hardware in new vehicles.
This complexity requires more analysis of the system specification, looking at the workloads and benchmarking them on different hardware implementations. This is more than just running a particular network on the fastest possible chip.
Software tools can help design a network and explore its architecture to see which layers within it are causing efficiency problems. This is a different approach to taking digital signal processing tools that are used to manage the MAC units; instead they work to optimise the neural network first with the data and then map that to the MACs in the hardware.
Then there is the challenge of decoupling the training data design from the execution of the network. The data problem is in designing the workloads, having networks for performance and accuracy to show that the networks are performing efficiently across the widest possible use cases. This requires sophisticated tools for managing the training data and adding in the synthetic data to handle the edge and corner cases.
Neuromorphic AI
A neuromorphic, or spiking neural network (SNN), is a different design of AI. It is event-driven, so it is suitable for detecting images infrequently, typically once a second, rather than a video with a frame rate of 30 or 60 frames per second.

The latest processor design for spiking neural networks uses six microprocessor cores, up from three, and 128 fully asynchronous neuron cores connected by a network-on-chip. The neuron cores are optimised for neuromorphic workloads, each implementing a group of spiking neurons, including all the connections between the neurons.
All the comms between the neuron cores is in the form of asynchronous spike messages, which are triggered only by an event.
The processor cores are optimised for spike-based comms and execute standard C code to assist with data I/O as well as network configuration, management and monitoring. Parallel I/O interfaces extend the on-chip mesh across multiple chips – up to 16,384 – with direct pin-to-pin wiring between neighbours.
A spike I/O module at the edge of the chip provides configurable hardware-accelerated expansion and encoding of input data into spike messages, reducing the bandwidth required from the external interface and improving performance while reducing the load on the embedded processors.
Hardware such as a field programmable gate array can be used to convert the asynchronous output of the SNN to the synchronous output needed by standard interfaces such as Ethernet.
SDNN

The asynchronous nature of spiking neural networks requires different software tools and libraries to deep neural networks (DNNs), which can make moving from one to the other a challenge.
The hardware has therefore been adapted for a DNN implementation known as the Sigma-Delta Neural Network (SDNN). This provides faster detection and higher efficiency than the SNN approach commonly used. SDNNs compute weights in the same way as conventional DNNs, but they only communicate significant changes as they happen, in a sparse and event-driven manner.
Simulations have shown that SDNNs can improve the performance of DNN workloads by more than 10 times in both inference speeds and energy efficiency.
Rather than optimising for a specific SNN or SDNN model, the hardware implements neuron models with a programmable pipeline in each neuromorphic core to support common arithmetic, comparison and program control flow instructions. This programmability greatly expands its range of neuron models using a dedicated software tool.
This software tool is an open, modular and extensible framework for spiking AI designs that allows engineers to converge on a common set of tools, methods and libraries. It runs on existing mainstream and neuromorphic processors, enabling cross-platform execution and interoperability with a variety of AI, neuromorphic and robotics frameworks.
That allows developers to start neuromorphic applications without access to specialised neuromorphic hardware, and then running on specialist chips and boards when they become available.
One of the first of these hardware systems is a stackable eight-chip system board with an Ethernet interface. It is aimed at portable projects with low power consumption such as UAVs with exposed general-purpose I/O pins and standard synchronous and asynchronous interfaces for integration with sensors and actuators. The boards can be stacked to create larger systems in multiples of eight chips.
Conclusion
Driverless cars are a major area of development for AI in uncrewed systems, and the DNN frameworks used for image analysis dominates the technology landscape. This technology is evolving from ADAS driver assistance to full safety-certified Level 4 and Level 5 autonomous driving, with a wide range of software tools and increasingly high-performance hardware for training the networks and for inference in a vehicle.
These capabilities are extending to other applications for UAVs, from positioning and monitoring functions for wind turbines to alternative navigation tools.
But there are other AI approaches that can also be used for image analysis in systems that require low power. The hardware and software tools for spiking are also evolving to give engineers more options for the control systems that guide autonomous systems.
Acknowledgements
The author would like to thank Miguel Angel de Frutos at UAV Navigation, Kostas Karachalios at Perceptual Robotics, Mustapha Ail at AImotive and Danny Shapiro at Nvidia for their help with researching this article.
Examples of AI manufacturers and suppliers
FRANCE
| exail (previously iXblue) | +33 1 30 08 88 88 | www.exail.com |
| Kalray | +33 4 76 18 90 71 | www.kalrayinc.com |
DENMARK
| Lorenz Technology | +45 66 80 60 56 | www.lorenztechnology.com |
HONG KONG
| Crystal Group | +852 2261 8888 | www.crystalgroup.com |
HUNGARY
| AImotive | +36 1 7707 201 | www.aimotive.com |
IRELAND
| Aptiv | – | www.aptiv.co |
ISRAEL
| Mobileye | +972 2 541 7333 | www.mobileye.com |
JAPAN
| Murata | +81 75 951 9111 | www.murata.com |
NETHERLAND
| SNXP | – | www.nxp.com |
SWEDEN
| Skyqraft | +46 73 914 65 57 | www.skyqraft.com |
| Zenuity | +46 31 31 36 000 | www.zenuity.com |
UK
| ARM | +44 1223 400400 | www.arm.com |
| Imagination Technologies | +44 1923 260511 | www.imgtec.com |
| Perceptual Robotics | +44 117 230 9745 | www.perceptualrobotics.com |
USA
| Intel/Habana Networks | +1 408 765 8080 | www.intel.com |
| Iris Automation | – | www.irisonboard.com |
| Neurala | +1 617 418 6161 | www.neurala.com |
| Nuro | – | www.nuro.ai |
| Nvidia | +1 408 486 2000 | www.nvidia.com |
| Overwatch Imaging | +1 541 716 4832 | www.overwatchimaging.com |
| Pony.ai | – | www.pony.ai |
| Qualcomm Technologies | – | www.qualcomm.com |
| Shield.ai | +1 619 719 5740 | www.shield.ai |
| Sightline Applications | +1 503 616 3063 | www.sightlineapplications.com |
| Skydio | +1 855 463 5902 | www.skydio.com |
| SparkCognition | +1 844 205 7173 | www.sparkcognition.com |
| Versalogic | +1 503 747 2261 | www.versalogic.com |
| Waymo | – | www.waymo.com |
| AMD/Xilinx | – | www.xilinx.com |
UPCOMING EVENTS







