







Video encoding

AI offers a range of benefits for compressing video from uncrewed systems, but as Nick Flaherty reports, traditional methods will prevail for now
Video encoding technology is undergoing a fundamental shift to reduce the bandwidth and improve the latency without impacting on the quality of the output.
Video compression has been based on mathematical computations of blocks using motion estimation techniques to reduce the amount of data that needs to be sent. Since the first mainstream international video encoding standard was approved nearly 40 years ago, as IEEE H.262 MPEG2 for digital TV broadcasts, uncrewed systems have been using mainstream encoder and decoder chips and software.
This has evolved into H.264 Advanced Video Coding (AVC), the mainstream video compression technology. As uncrewed systems, especially UAVs, need to send higher resolution 4K video, so the encoders are adopting H.265 High Efficiency Video Coding (HEVC) technology.

Video is used for various applications, leading to differing requirements for the encoding system. When sending video from a camera on a UAV for monitoring or situational awareness, the video quality is key. But this can also be achieved using analysis on the aircraft to zoom in on a region of interest and encode it with higher quality.
The technology is also being used to combine video into augmented reality (AR) alongside other navigation and system data from the UAV, allowing the use of smaller video frame sizes and so reducing the load on the link.
This video often also needs to be stored, either on the platform or in a cloud service. Techniques to reduce the amount of data that needs to be stored in a way that can recreate the detail when required can be a key part of the system architecture.
There is also demand for higher quality for full frames of video coupled with low latency. Remotely operated vehicles, whether in the air or on the ground, require that the operator can see as much of the surrounding environment as possible. As the camera sensors are moving to 4K resolution, so the demand on the encoder to deliver the video stream in real time over an existing radio link without losing or dropping frames is a major challenge.
This drive to squeeze more video over wireless links has driven the development of the latest standard, H.266 or Versatile Video Coding (VVC), approved last year. Block-based encoding works well on scenes where there is limited change from frame to frame, which is suitable for uncrewed control systems, but dynamic scenes with a lot of complex movements can overwhelm the encoder or the wireless link.
However, this is currently implemented as software in power-hungry dual-core processors or as hardware in expensive FPGA chips, which again can be power-hungry. These devices can be used in larger UAVs or driverless cars, and the current devices combine four processor cores with the programmable logic fabric to reduce costs.
In previous generations of the technology, the encoding and decoding functions have gone on to be implemented directly in silicon to provide standard conversion with low power and lower cost. For uncrewed systems however, that cycle of development for lower cost and lower power has slowed, and there is another major technology factor that is set to change the direction of development.
Machine learning (ML), or AI, algorithms are now being applied to the video before encoding to reduce the amount of data that needs to be processed, and even to use different techniques for encoding the images, such as describing a scene in text and using generative AI to regenerate the scene at the other end.
ML is considered an essential new tool in the progress towards future codecs. Its techniques are under scrutiny by the major video standards organisations, including the MPEG JVET Ad hoc Group 11 (AhG11). This group, part of the same organisation that developed the previous compression technologies, is looking at new standards with AI at the centre of the coding scheme and examining related ML techniques that can be used to boost existing encoders.
This work has been named Neural Network Video Coding, to create an AI-based codec before the end of the decade. This is looking at the use of ML for encoding more dynamic scenes, and could uncover entirely new methods for coding and transmission. In the short term, ML is being used to enhance existing coding tools, allow encoders to work on partial frames, and to determine areas within each frame that are least consequential so that they can be compressed more than the others.
Therefore, one of the key elements in the work of JVET AhG11 is to develop a framework capable of fully specifying, evaluating and comparing the outputs of AI-based algorithms. In essence, JVET is establishing clear rules by which AI methods can be assessed and made reproducible.
Inevitably though, as AI-based methods continue to evolve, it is abundantly clear that the technology will become deeply entrenched in video encoding and decoding solutions. That goes beyond existing audio-visual applications, as more video will be consumed by the processors in the vehicles and robots. This will lead to AI-driven codecs with different adjustments for human and machine interpretation.
In the longer term, ML could be used to generate video frames based on reference images, video context and metadata descriptions that together build a credible approximation of the original video.
New methods of creating video are expected to emerge, first for broadcast and then for embedded wireless links for UAVs and autonomous vehicles on the road. Generative AI can create convincing audio and visual assets entirely artificially, so the future for video coding has to consider synthetic media.

Codecs are already being launched that don’t compress a video file but reconstruct it based on context and reference images, to preserve quality despite a drastic reduction in file size. This can be particularly relevant for remotely operated road vehicles. This synthetic data can protect the identity of other road users by removing any identifiable features while still delivering the accurate situational awareness a remote operator needs.
Bandwidth-friendly
By sending only the base information of each frame as mathematical elements rather than pixels and rebuilding frames on the fly, ML compression is bandwidth-friendly and can scale infinitely to any size of display.
This scaling significantly reduces the demand on the feed from the uncrewed system. Video content encoded by an AI codec can be rebuilt from scratch to fit any resolution and frame rate.
New immersive formats for video for VR and AR are being developed. In these applications, low latency is of paramount importance since noticeable delays in video encoding or decoding not only destroy the levels of immersion but can lead to operator nausea and sickness.
Sensors on VR headsets are being developed to operate in tandem with video processing engines to reduce so-called motion-to-photon latency. Further, solutions in video coding for 360o video capture and rendering aim to reduce the computational load necessary.

Techniques such as foveated rendering provide a shortcut by encoding portions of each frame at full resolution, depending on where the viewer is concentrating on. However, the computational requirements are so high that many headsets have to be tethered to high-performance PCs for the visual processing.
To address this, the end-to-end video (EEV) coding project from MPAI (Moving Picture, Audio and data coding by AI) is developing technology and specifications to compress video in UAV applications by exploiting AI-based data coding technologies. Since its set-up at the end of 2021, the MPAI EEV has released three major versions of its reference models. The aim is to provide a solid baseline for compressing UAV video.
The volume of video captured by UAVs is growing exponentially, along with the increased bitrate generated by advances in the sensors on UAVs, bringing new challenges for on-device UAV storage and air-to-ground data transmission. Most existing video compression schemes were designed for natural scenes, without considering specific texture and view characteristics of UAV videos.
The project analysed the technology landscape for encoding, and is developing a learned UAV video coding codec with a comprehensive and systematic benchmark for the quality of the resulting video.
To reveal the efficiency of UAV video using conventional as well as learned codecs, video sequences were encoded using the HEVC reference software with screen content coding (SCC) extension (HM-16.20-SCM-8.8) and the emerging learned video coding framework OpenDVC.
The reference model of MPAI EEV is also used to compress the UAV videos, leading to baseline coding results for three different codecs.
Another important factor for learned codecs is train-and-test data consistency. It is widely accepted in the ML community that train and test data should be independent and identically distributed.
However, both OpenDVC and EEV are trained using the natural video dataset vimeo-90k with mean square error as distortion metrics. The project used these pre-trained weights of learned codecs without fine-tuning them on UAV video data to guarantee that the benchmark is the general case rather than a tuned version.
The comparison of the codecs used the peak signal-to-noise ratio (PSNR) for every red/green/blue (RGB) component in each frame, with the average RGB value giving the picture quality. The bitrate is calculated on a bit-per-pixel basis using the binary files produced by codecs.
The video encoding performance of EEV and HEVC shows an obvious performance gap between the indoor and outdoor sequences. In general, the HEVC SCC codec outperforms the learned codec by 15.23% over all videos. Regarding Class C, EEV is inferior to HEVC by a clear margin, especially for the classroom and elevator sequences. This shows that the learned codecs are more sensitive to variations in the video content than conventional hybrid codecs.
This agrees with the industry view that traditional coding tools outperform AI-based alternatives in most areas.
One reason for this is that ML codecs can be several orders of magnitude more complex than traditional ones. Neural networks are being used within traditional codecs to replace existing tools, especially where performance is likely to be improved, but the complexity is often exceptionally high. In this instance, ML creates new algorithms that people couldn’t conceive or would otherwise be challenging to program.
Increased algorithm complexity leads to potentially unseen or indirect consequences, as the computer processing time and computing performance is proportional to energy use.
There are other challenges for ML-based video development. Existing video standards offer reference software, common test conditions and frame sequences, alongside prescribed ways to demonstrate performance and quality that allow direct comparison of various executions in hardware or software. Essentially, the video standard is fully described and verified against agreed metrics.
When using ML, it is sometimes difficult to explain exactly how the implementation operates. While it is perfectly feasible to have flexibility in the final implementation, there must be an understanding of how AI-based algorithms adhere to the specifications and produce standards-compliant bitstreams.
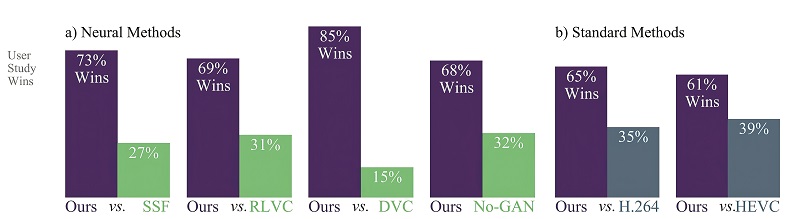
Researchers at Google have used a set of ML tools, including general adversarial networks (GANs), to enhance the development of ML video compression algorithms. This approach uses ML to generate new algorithms and test them against each other to converge on new, more efficient techniques.
The compression is achieved by exploiting similarities among video frames. This is possible because most of the content is almost identical between frames, as a typical video contains 30 frames per second. The compression algorithm tries to find the residual information between the frames.
Despite achieving impressive compression performance, neural video compression methods suffer when producing realistic outputs. These can generate the output video close to the input, but miss the realism.
The goal of adding the realism constraint for neural networks is to ensure the output is indistinguishable from real images while staying close to the input video. The main challenge is ensuring the network can generalise well to unseen content.
The researchers constructed a generative neural video compression technique that excels in synthesis and detail preservation using the GAN.
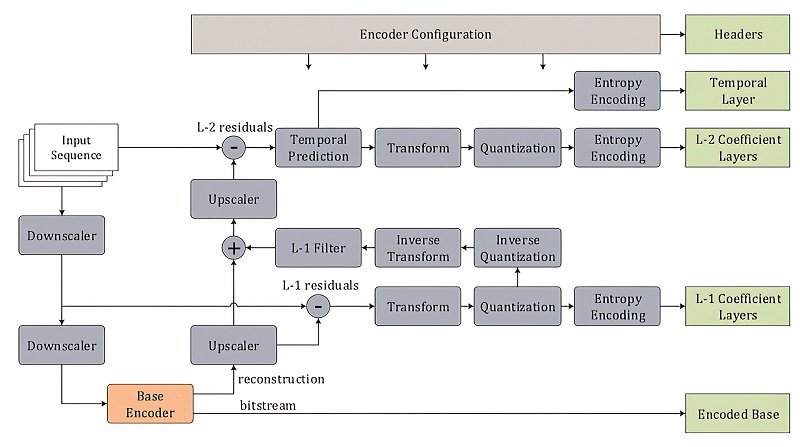
In video compression, specific frames are selected as key frames (I-frames) that are used as a base for reconstructing upcoming frames. The frames are allocated higher bitrates and so have better details. This is also valid for the proposed method that synthesises the dependent frames (P-frames) based on the available I-frame in three steps.
First, the ML network synthesises essential details within the I-frame, which will be used as a base for upcoming frames. This is done by using a combination of convolutional neural network and GAN components. A discriminator in the GAN is responsible for ensuring I-frame level details.
Second, the synthesised details are propagated where needed. A powerful optical flow method called UFlow is used to predict movement between frames.
The P-frame component has two auto-encoder parts, one for predicting the optical flow and one for the residual information. These work together to propagate details from the previous step as sharply as possible.
Finally, an auto-encoder is used to determine when to synthesise new details from the I-frame. Since new content can appear in P-frames, the existing details can become irrelevant, and propagating them would distort the visual quality. So, whenever that happens, the network should synthesise new details. The residual auto-encoder component achieves this.
In a user study, this approach significantly outperformed previous neural and non-neural video compression methods, setting a new state of the art in visual quality for neural methods.
Traditional video compression
However, there is still plenty of focus on traditional compression technology in several respects.
The first silicon design to implement an MPEG-5 Low Complexity Enhancement Video Coding (LCEVC) decoder design block is boosting the development of more efficient chips.
MPEG-5 part 2 LCEVC is the latest standard from MPEG and the ISO. It specifies an enhancement layer which, when combined with a base video encoded with a separate codec such as H.264, HEVC or VVC, produces an enhanced video stream. This stream provides new features such as extending the compression capability of the base codec, lowering encoding and decoding power consumption, and providing a platform for additional future enhancements.
The latest LCEVC decoder IP supports picture resolution up to 8K, pixel widths from 8 to 12 bits and chroma sub-sampling formats ranging from 4:2:0 up to 4:4:4. The IP also features fast and easy integration into a chip and is delivered with fully user-configurable control software.

The latest low-bandwidth H.265 video encoders support low-latency video streaming at up to 4K resolutions. Users can choose H.265, H.264 or motion JPEG (MJPEG) that compresses each frame individually for the video compression, with configurable bitrates, encoding profiles and the option for embedded digital or analogue audio.

H.266/VVC uses the same underlying architecture as HEVC but brings enhancements to each of the coding tools. The enhancements include video frame structuring to allow the encoder to focus on specific areas of less interest for higher compression to reduce the overall bit rate.
A common approach uses the fact that successive frames in a video are often visually comparable and can be efficiently predicted from preceding reference frames by motion compensation, called temporal prediction.
When temporal prediction is used, the coded signal is the difference between the blocks of the frame to be encoded alongside the predicted motion of the block. Video codecs exploit this by only sending some independently coded frames (the I-frames or key frames) along with frames using temporal prediction that refer to already decoded frames.
VVC improves the motion vector prediction compared to HEVC, reducing the coding overhead for determining the motion vectors. It supports two motion vector prediction methods, Merge Mode and AMVP Mode. In both modes, a list of candidate motion vectors is built, and an index is signalled to indicate which candidates to pick from the list for deriving the final motion vectors.
Frames are examined and subdivided into smaller sections for processing. Like HEVC, VVC uses coding tree units that can be divided into smaller coding units but has larger block structures of up to 128 x 128 pixels. VVC can combine several blocks into logical areas defined as tiles, slices and sub-pictures so that the decoder might elect to decode only the areas of the video that are necessary, such as in the application of panoramic and 360o video, where the viewer might see only a small section of the entire frame.
In HEVC, there was a single tree structure that allowed the splitting of each square block into four square sub-blocks recursively. VVC extends this, allowing each block to be further subdivided horizontally and vertically into two or three smaller elements. Applying this technique improves the adaptation of the encoder to the input, but at the expense of a considerable increase in the complexity of the video coding process.

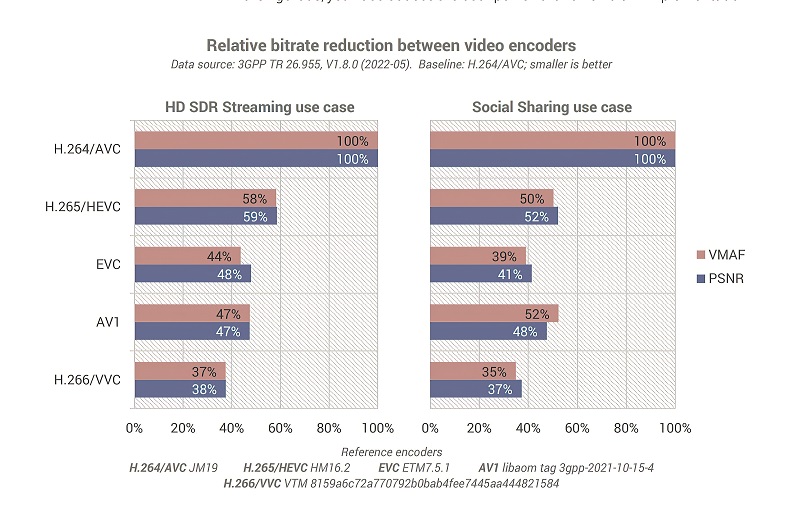
The latest real-time VVC software encoder for 4Kp60 60 frames/second video now gives an 18% bitrate saving at equal quality compared to the HEVC real-time encoder. For 8Kp30 30 fps streams, the saving is 27%.
For standard resolution, the difference is even greater, at 40%, but this gets better over time as the implementation of VVC is improved. Over the years, for example, HEVC has improved the compression efficiency by more than 100%.
Released at a similar time as VVC, Essential Video Coding (EVC) is an MPEG standard positioned as a competitor to AV1, with a workable licencing model. For the baseline profile, only tools guaranteed to be royalty-free are being integrated. EVC provides a 20-25% efficiency gain over HEVC.

Hybrid AI encoding
Conventional video encoders are also adding AI-based preprocessing in software to improve the quality and bitrate efficiency of conventional encoders. Some require a post-processing component, but with others it is optional.
This allows developers to combine existing hardware encoders with AI on the platform and the ground station to improve the quality of the video link without having to re-qualify the system. The developers say the changes to details in the video feed are not visible but reduce the bitrate that the encoder has to work on, reducing the time taken and thus improving the latency.
This can also be combined with embedded AI accelerator chips that are being integrated into the next generation of uncrewed system designs. The chips are dedicated AI acceleration engines with a focus on lower power consumption, initially aiming at onboard video processing for automotive ADAS safety systems and driverless car systems.
These low-power AI chips however can also be used to run AI algorithms for pre-processing the video feed to reduce the bandwidth required in the uncrewed system and also for the wireless link.
Conclusion
AI algorithms are a major area of research for video compression, the uncrewed systems benefiting from the focus on reducing the bandwidth required to carry high-resolution video in many different ways.

AI-only implementations still have some way to go before they are more efficient than traditional H.265 HEVC compression technology. However, AI pre-processing algorithms combined with the more configurable block encoding of H.266 VVC opens up major advantages for reducing the bandwidth required for video compression for all kinds of uncrewed systems.
Acknowledgements
The author would like to thank Guido Meardi at V-Nova and Florian Maurer at Aachen University for their help with researching this article.
UPCOMING EVENTS



