







AI
(Image: NVIDIA)
Transforming autonomous vehicles
Transformer AI models are changing the way autonomous vehicles are controlled, as Nick Flaherty finds out
There are many different types of AI framework, from convolutional neural networks used for deep learning to transformers that are used for large language models and, increasingly, for vision processing. The use of these frameworks for autonomous vehicles is evolving, in terms of both software and hardware.
This is influencing the underlying hardware. Transformers were originally optimised for general purpose graphics processing units (GPUs), but now embedded hardware is implementing specific transformer-based models to reduce power consumption.
Software for autonomous driving is built on frameworks that handle the massive data flow from sensors (e.g., Lidar, cameras and radar) and translate it into driving commands. The latest shift is toward end-to-end neural networks. Instead of separate modules, the entire driving process is handled by a single, massive AI model (often using Vision Transformers or Large Multimodal Models). This allows the car to ‘reason’ through complex scenarios rather than to follow hard-coded rules.
Before a vehicle is deployed, the software is tested in virtual environments. The AI is developed and trained on a development framework, while the inference engine is where the AI is optimised to run on the car’s hardware in real time.
Development frameworks include PyTorch, TensorFlow, JAX (which is used by Waymo for its self-driving technology) and Keras, which acts as a ‘bridge’ framework, allowing developers to write code once and then run it on top of PyTorch, TensorFlow or JAX backends.
However, once a model is trained, it is too large to run on a car’s processor; therefore, these frameworks compress and optimise the AI for millisecond-speed execution. Tools such as TensorRT, OpenVINO and ONNX (Open Neural Network Exchange) are used to optimise the models to fit the application.
TensorRT optimises the neural networks specifically for the GPU to ensure that commands are executed in real time. OpenVINO is used primarily to optimise vision models to run efficiently on CPUs and integrated accelerators. ONNX allows a model trained in PyTorch to be ‘exported’ and run on almost any automotive hardware.
Specialist AI architectures

Beyond the general frameworks, specific AI frameworks are used for different driving tasks (see table above).
Multimodal LLMs (DriveMLM)
In late 2024 and throughout 2025, a new framework category emerged called Large Multimodal Models for Driving. These frameworks allow the car to not just ‘detect’ a ball but to ‘reason’ like a human: for example, “There is a ball in the street, so a child might run out next; I should slow down.”
PyTorch is preferred for development because it handles tensors (multidimensional data) efficiently on GPUs. In an autonomous vehicle, the perception pipeline typically follows the following steps:
1. Data Loading: High-resolution images from cameras and 3D point clouds from Lidar are loaded using PyTorch’s DataLoader.
2. Backbone Network: A model like ResNet or a Vision Transformer (ViT) extracts features (e.g., edges, shapes and distances) from the raw pixels.

3. Head Modules: Specialised ‘heads’ are attached to the network to perform specific tasks. These include object detection for identifying pedestrians, cars and cyclists, as well as semantic segmentation that colours every pixel to identify ‘drivable’ surfaces. Depth estimation predicts how far away an object is using only 2D camera images.
4. In the training loop, engineers use a ‘Loss Function’ to tell the AI when there is an error, such as a stop sign being missed. The model then uses backpropagation to adjust its internal weights to be more accurate next time.
Reinforcement Learning (RL)
If PyTorch builds the ‘eyes’, Reinforcement Learning (RL) builds the ‘experience’. Unlike traditional programming where you give a car a thousand ‘If/Then’ rules, RL allows the car to learn by trial and error in a simulator.
The vehicle interacts with a virtual environment through a continuous loop. In the observation state, the car ‘sees’ its current situation – its speed, the distance to the car in front and the curve of the road. The car then decides to do something: steer 5 degrees left, brake or accelerate.
The reward is the most critical part. The system gives the car ‘points’ based on the outcome. For example, +10 points for staying in the centre of the lane, +50 points for reaching the destination safely or -100 points for causing a collision or crossing a double line. The car then analyses its actions to determine those that led to the highest rewards and updates its policy – the driving strategy.
LSTM models
A LSTM (Long Short-Term Memory) model is a specialised type of AI – specifically, a recurrent neural network – designed to recognise patterns in sequences of data over time.
This is used primarily for tasks where temporal context is just as important as visual data.

In autonomous driving (AD), an LSTM acts as the vehicle’s ‘short-term memory’. While standard AI might look at a single photo and say: “That is a car,” an LSTM looks at the last 5 seconds of video and says: “That car is accelerating and likely about to cut into my lane.”
Standard neural networks suffer from ‘forgetting’ what happened just a moment ago in a continuous flow of events. Conversely, LSTMs overcome this using three ‘gates’ that control information flow:
• Forget Gate: Decides what information from the past is no longer relevant (e.g., a car that turned off the road 10 seconds ago).
• Input Gate: Decides what new information is worth remembering (e.g., a pedestrian just stepped off the curb).
• Output Gate: Decides what the car should do right now based on its combined memory and current view.
Commonly, an LSTM is used for trajectory prediction, where the model analyses the historical coordinates of surrounding vehicles to predict where they will be in the next 3–5 seconds. For example. by ‘remembering’ the slight swerve of a cyclist, the LSTM predicts that they are avoiding a pothole and so will steer back into the centre of the lane.
The AI also uses LSTMs to classify the ‘intent’ of other drivers. For example, on seeing a car slowing down near an intersection without an active indicator, the LSTM identifies the pattern of ‘slowing + approaching turn’ and classifies the manoeuvre as an ‘unannounced right turn’, allowing the autonomous car to brake early.
Cars receive data at different speeds, with cameras producing data at 30 fps and Lidar at 10 fps. LSTMs help smooth these data over time so that the car’s understanding of its own position doesn’t jump or flicker.
Transformers
The transformer model, first described in 2017, is a neural network that learns context and thus meaning by tracking relationships in sequential data. It applies an evolving set of mathematical techniques, called attention or self-attention, to detect subtle ways that data elements in a series influence and depend on each other.
Transformers, sometimes called foundation models, are already being used with many data sources for a host of applications, from text and video generation to exploring new materials for batteries, and they are replacing existing networks.
(Image: NVIDIA)
Before transformers, training neural networks required large, labelled datasets that were expensive and slow to develop. Transformers use mathematical patterns to reduce this need and work effectively with synthetic data from simulators. Their design also enables fast parallel processing.
Transformer models, like other neural networks, use encoder/decoder blocks to process data. Strategic modifications enhance their performance. Positional encoders tag data, and attention units map relationships between elements. Multi-headed attention executes queries in parallel, enabling vehicle sensors to detect patterns similar to those perceived by humans.
Although Transformer architecture is used widely in natural language processing, its adoption in computer vision has been less common. However, pure transformers like ViT can now handle image patches directly and deliver strong classification results with less training resources, outperforming leading convolutional networks on benchmarks such as ImageNet, CIFAR-100 and VTAB.
LSTM vs. Transformer
While LSTMs were the gold standard for years, the industry is shifting toward transformers. Many systems today use Conv-LSTM layers, which combine the visual capability of convolutional neural networks (CNNs) with the temporal memory of LSTMs to ‘see’ and ‘remember’ simultaneously.
This move to transformer models has led to a new generation of hardware optimised for transformer vision applications, particularly for ‘Bird’s-Eye View’ (BEV) perception.
End-to-end models
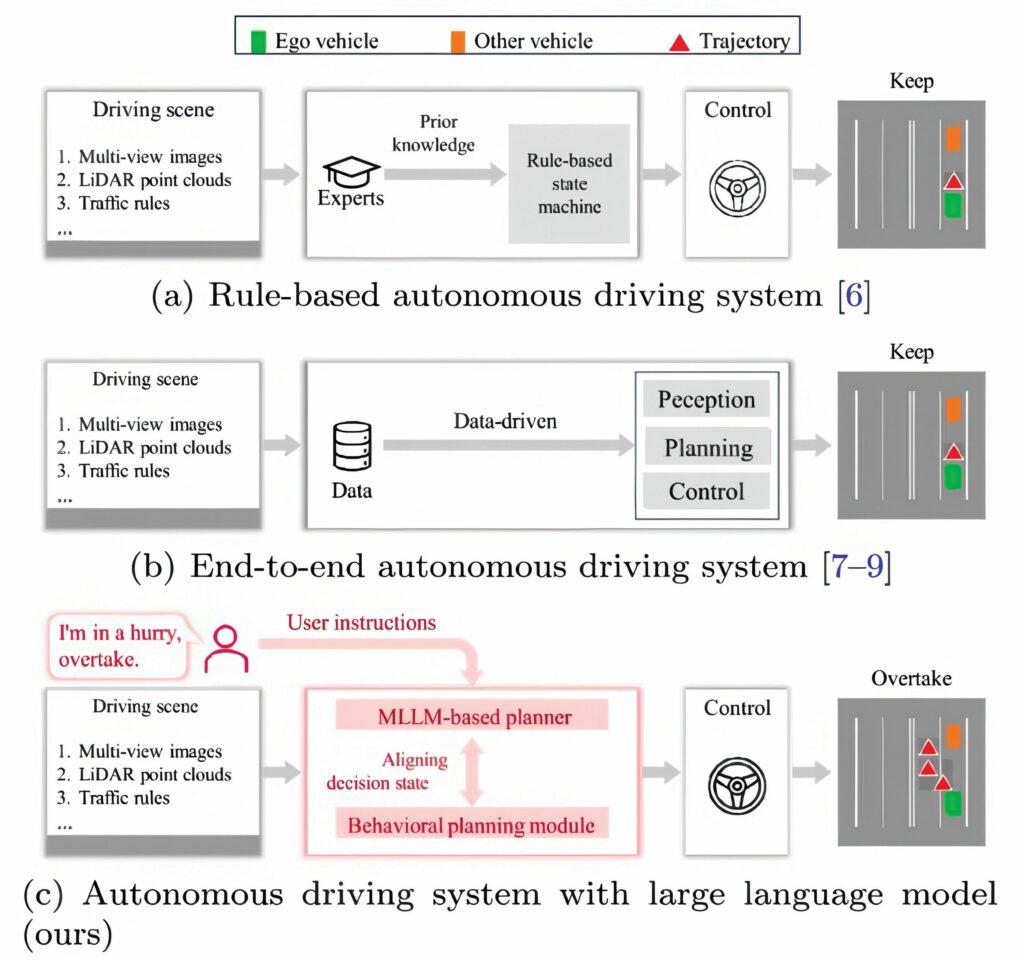
End-to-end models still face major deficits: they often lack world knowledge, struggle in rare or ambiguous scenarios and provide minimal insight into their decision-making process. Large language models (LLMs), by contrast, excel at reasoning, contextual understanding and interpreting complex instructions. However, LLM outputs are linguistic rather than executable, making integration with real vehicle control difficult. These gaps highlight the need for frameworks that combine multimodal perception with structured, actionable decision outputs grounded in established driving logic. Addressing these challenges requires deeper research into aligning multimodal reasoning with autonomous driving planners.

A multimodal LLM framework for closed-loop autonomous driving called DriveMLM integrates multiview camera images, Lidar point clouds, system messages and user instructions to produce consistent, aligned behavioural planning states. These states plug directly into existing motion-planning modules, enabling real-time driving control while generating natural-language explanations of each decision.
DriveMLM tackles a core challenge in LLM-based driving: converting linguistic reasoning into reliable control behaviour. The framework aligns LLM outputs with the behavioural planning states used in modular systems such as Apollo, covering both speed decisions (KEEP, ACCELERATE, DECELERATE and STOP) and path decisions (FOLLOW, LEFT_CHANGE, RIGHT_CHANGE and others).
A specialised multimodal tokeniser processes multiview temporal images, Lidar data, traffic rules and user instructions into unified token embeddings. A multimodal LLM then predicts the appropriate decision state and produces an accompanying explanation, ensuring interpretability.
To support training, a large-scale data engine generated 280 hours of driving data across eight maps and The R-car 30 challenging scenarios, including rare safety-critical events, in the open-source CARLA simulator. The pipeline automatically labels speed and path decisions, and uses human refinements and Generative Pre-trained Transformer (GPT)-based augmentation to produce rich explanatory annotations.
In closed-loop evaluation on the CARLA Town05 Long benchmark, DriveMLM achieved a Driving Score of 76.1, outperforming the baseline of the mainstream Apollo software by 4.7 points, and it recorded the highest miles per intervention (0.96) among all compared systems. DriveMLM also demonstrated strong open-loop decision accuracy, improved explanation quality and robust performance under natural-language guidance – such as yielding to emergency vehicles or interpreting user commands like ‘overtake’ under varying traffic conditions.
The research showed that LLMs, once aligned with structured decision states, can serve as powerful behavioural planners for autonomous vehicles. DriveMLM goes beyond rule-following; it understands complex scenes, reasons about motion and explains its decisions in natural language – capabilities essential for safety and public trust. By combining perception, planning and human instruction within a unified framework, DriveMLM can be used for next-generation autonomous driving systems.
DriveMLM demonstrates how multimodal LLMs can enhance transparency, flexibility and safety in autonomous driving. Its plug-and-play design allows seamless integration into established systems such as Apollo or Autopilot, enabling improved decision-making without major architectural changes. The ability to interpret natural-language instructions expands possibilities for interactive driving assistance and personalised in-vehicle AI copilots. More broadly, DriveMLM highlights a path toward reasoning-driven autonomous systems capable of understanding complex environments, anticipating risks and justifying their actions.
Driving safety
A newly developed ‘Physical AI-based Vehicle State Estimation Technology’ accurately estimates the driving state of electric vehicles in real time to improve the safety of autonomous vehicles.
(Image: Ambarella)
The ‘Sideslip Angle’, which shows how much an electric vehicle slides sideways during sharp turns or on slippery surfaces, is crucial information for safe driving. This value is difficult to measure directly with in-vehicle sensors, so developers depend on complex physical models or indirect estimates. These methods can lack accuracy and can be limited across different driving conditions.
(Uncrewed Systems)
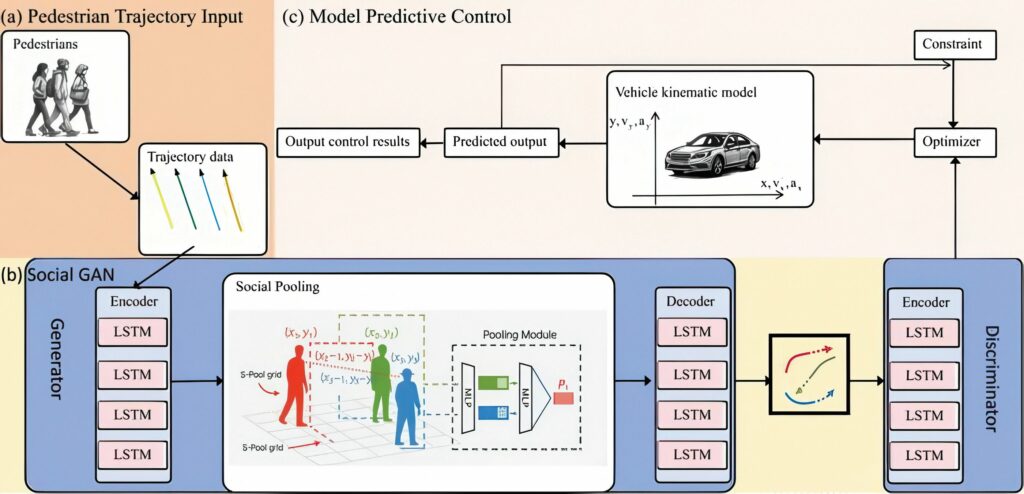
One way to address these issues is to combine AI and physical models. The main idea is that it significantly enhances accuracy by merging a physical model describing vehicle motion with data from sensors measuring lateral tyre force and an AI-based regression model.
To address nonlinear tyre behaviour and environmental changes that are difficult for physical models to explain, a hybrid estimation framework combines a physical tyre model with an AI-based learning model. This combines a Kalman filter integrated with Gaussian process regression to tap into the flexibility of data-driven learning and the reliability of the physical model. This combination enables more accurate and faster estimation of the vehicle’s slip angle compared with traditional methods.
In testing, this technology shows high accuracy and strong estimation performance across different road surfaces, speeds and cornering conditions.
(Image: Shanghai Jaio Tong University)
The framework has been experimentally validated using a full-scale vehicle equipped with in-wheel motors and lateral tyre force sensors. The results confirm that the approach achieves accurate and stable sideslip angle estimation during aggressive manoeuvres and across varying road surfaces. This enables high-fidelity, real-time state estimation for advanced driver-assistance and automated driving applications, and opens new possibilities for AI-based physical vehicle control. Researchers are working with global car makers to expand the technology into vehicles.
Cause and effect

AI can also be used to improve how machines learn from past data with offline reinforcement learning. This type of AI is essential to allow systems to make decisions using only historical information without needing real-time interaction with the world. By focusing on the authentic cause-and-effect relationships within the data, a new method enables autonomous vehicles to make safer and more reliable choices.
Traditionally, offline reinforcement learning has struggled because it sometimes picks up misleading patterns from biased historical data. With the ability to identify genuine cause-and-effect relationships, the new approach makes autonomous systems much safer and more dependable.
Traditional AI models sometimes mistake unrelated actions as causally linked, which can result in dangerous outcomes. It has been demonstrated that many of these errors are significantly reduced by incorporating causal structure into these models. Moreover, the new method – referred to as a new causal AI approach – has been shown to perform consistently better than existing techniques when tested in practical scenarios.
This is achieved using specialised statistical tests designed for sequential and continuous data. This approach helps accurately discern the true causes behind observed actions and reduces the computational complexity that often hampers traditional methods, making the system more efficient and practical.
Socially aware driving
Other researchers have developed a socially aware prediction-to-control pipeline that lets autonomous vehicles safely navigate dense crowds by anticipating multiple ways pedestrians might move.
Instead of betting on a single forecast, their system combines a trajectory predictor using a general adversarial network (GAN) with a real-time model predictive control (MPC) planner, treating each predicted path as a moving obstacle. In dynamic crowd simulations, the integrated GAN+MPC controller achieved zero safety violations and maintained comfortable motion, all while meeting strict real-time computing limits. This offers a practical route toward zero-collision autonomous driving in busy urban environments.
In dense urban spaces, self-driving systems must make split-second decisions while surrounded by other drivers who may suddenly slow down, speed up or change direction.
The socially aware prediction-to-control framework helps autonomous vehicles weave through crowds without collisions.
Traditional motion planners often assume that pedestrians behave in simple, predictable ways. In practice, people negotiate for space, join or split groups, pause to look at their phones or yield to others at the last moment. These behaviours are inherently uncertain and multimodal: at any given instant, several different paths may be equally likely.
For computational reasons, many existing systems compress this rich uncertainty into a single ‘average’ forecast or a conservative worst-case path. While this simplification makes the planner easier to implement, it can also make the vehicle overly cautious – stopping too often – or dangerously overconfident if the behaviour deviates from the single predicted future.
The new framework positions itself exactly at the interface between learning-based prediction and optimisation-based control.
On the prediction side, the Social GAN model takes short histories of pedestrian motion and generates multiple socially consistent future trajectories for each person in the scene. These samples capture distinct possibilities such as ‘keeps walking straight’, ‘slows down’ or ‘yields and turns’ instead of collapsing everything into a single path.
(Image: Shanghai Jiao Tong University/Henan University)
On the control side, an MPC planner computes the vehicle’s next steering and acceleration commands over a short time horizon while respecting physical limits and comfort constraints. The key innovation is to treat each GAN trajectory sample as a time-varying dynamic obstacle inside the MPC optimisation problem. Rather than smoothing the trajectories into a probability map or averaging them, the planner explicitly considers a curated set of diverse futures when choosing its own path.
In simple terms, the predictor imagines several socially reasonable futures for every pedestrian, and the controller picks a path that stays safe under all of them. This lets the vehicle negotiate crowded spaces more like a cautious human driver, without needing an excessively complex controller.
To test the framework, the team first validated the GAN’s predictive quality on standard pedestrian datasets, where it outperformed classic LSTM-based baseline models in average and final displacement error. They then placed a robot agent into simulated dense-crowd scenarios and compared two control strategies.

The first was a simple reactive ‘emergency-stop’ policy that brakes when pedestrians get too close, while the second was the proposed Social GAN-assisted MPC controller.
Both controllers used the same pedestrian predictions, but only the second treated the multiple trajectory samples as structured input to the optimisation problem.
In repeated simulations, the Social GAN+MPC controller achieved zero safety violations, maintaining an average clearance of about 0.94 m to the nearest pedestrian – slightly larger than the reactive baseline – while still reaching the goal. The safer behaviour came at the cost of only a small increase in travel time (about 0.8 seconds longer) and a modest reduction in path efficiency due to more cautious detours.
Because the controller makes earlier, proactive adjustments, it uses higher acceleration and jerk levels than the simple baseline. However, these values remain within commonly accepted comfort limits, indicating that passengers would likely perceive the manoeuvres as firm but not aggressive.
Crucially, the entire prediction-to-control loop remains fast enough for real vehicles. Across 40 full cycles, the average end-to-end latency was around 209 milliseconds, with the slowest cycle still comfortably below a 400 millisecond deadline. Social GAN itself required only a few milliseconds per update, while the MPC solver dominated the computation but stayed within typical 100–200 millisecond control intervals.
AI in UAVs
The restrictions on performance and power consumption have limited the use of AI onboard uncrewed aircraft. As a result, older optimised CNNs are used to identify and classify obstacles such as power lines, tree branches or other aircraft.
Simultaneous localisation and mapping (SLAM) uses AI to build a 3D map of an unknown environment while simultaneously tracking its own location within that map. This is essential for flying indoors or in tunnels where GPS is unavailable.

RL for flight control
UAVs use RL to master manoeuvres that are too complex for traditional programming techniques, as well as for adaptive flight. For example, if a UAV loses a propeller or faces extreme wind gusts, RL-based controllers can instantly ‘re-learn’ how to stabilise the aircraft by adjusting the speed of the remaining motors. RL can also be used to teach drones how to fly through narrow gaps at high speeds, allowing for faster response times in search-and-rescue applications.
Vision–language–action
The newest vision–language–action (VLA) frameworks allow operators to give UAVs high-level natural language commands. Instead of demanding: “Fly to GPS 40.7, -74.0,” an operator can tell the UAV: “Follow the red truck and notify me if it stops.” The AI uses an LLM framework to translate this text or even a voice command into visual tracking and flight path data automatically.
Acknowledgements
The author would like to thank Ashish Vaswani at Essential AI and Jifeng Dai at Tsinghua University for their help in researching this article.

UPCOMING EVENTS



