







Video systems

(Image courtesy of Teledyne FLIR)
Seeing is believing
AI is dramatically changing the way video is managed in uncrewed systems, as Nick Flaherty explores
The combination of AI and video encoding is transforming the development of uncrewed systems. Autonomous systems equipped with high-quality cameras can capture large amounts of video data; however, transmitting and storing such data in real time can be challenging owing to bandwidth limitations. Video encoding technologies can address this issue by compressing the video data without significant loss of quality.
Recent rapid advances in deep learning AI techniques for digital vision-based perception have converged with gains in computational imaging for image quality to produce innovations in mobile processors and device support. This convergence is creating opportunities for electro-optical systems to become intelligent at the edge and to eliminate issues with latency, compression artifacts, datalink bandwidth, thermal management and system complexity.
Advanced video encoding algorithms, such as H.264 and H.265 (also known as Advanced Video Coding and High Efficiency Video Coding, respectively), enable efficient compression and transmission of video data, allowing real-time streaming of high-definition video footage to ground stations or remote operators. Use of video encoding reduces the data storage requirements, thereby enabling longer flight times and more efficient data management. The successor standard H.266 (or Versatile Video Coding) reduces the bit rate further but has yet to be adopted in low-power embedded chips.
However, development has focused on using neural networks or AI on the video streams, rather than to achieve more compression. Using AI for data collection and analysis means that autonomous systems can capture high-resolution images and videos, and then use AI algorithms to process the stream to extract valuable information, thereby reducing the need for bandwidth and for compression technologies. For example, UAVs equipped with AI can identify objects, monitor crop health, detect anomalies in infrastructure or assist in search and rescue operations.

The combination of AI and video encoding technologies is also improving video analytics. AI algorithms can be applied to compressed video data, enabling real-time object detection, tracking and analysis. This allows UAVs to perform tasks such as automated surveillance, crowd monitoring or traffic analysis.
The combination of an ultra-small video encoder engine and an AI accelerator chip allows video to be processed in parallel, and means that data on tracking identification and classification can be layered over the video in near real time.
Decisions can be made based on these data or coordinates that can be output locally or sent to the ground via a wireless link. The AI data can be used locally to guide an autopilot or control a gimbal. The AI data sent to the ground, either visually or as raw data, can be used by the flight controller to navigate, steer or take decisions on the next course of action.
This opens up the prospect of an autonomous decision-making process. For example, weed detection and classification can allow crop spraying drones to target weeds rather than spraying entire fields. In a military environment, classification of targets allows autonomous decision-making regarding target selection.
A small low-power 50 x 25 x 15 mm module assembly is now capable of encoding multiple cameras, processing raw video through an AI accelerator chip, and performing real-time streaming and local recording.

(Image courtesy of Antrica)
A further innovation is the ability to record raw video, which can be used on the ground to develop new AI algorithms based on real video recordings with no compression for more accurate detection.
Manufacturers of UAVs and other autonomous vehicles are adding multiple camera technologies for differing situations. A zoom block can be used for detailed HD and 4K images (see below) but with an analogue zoom of 20-40x, in addition to thermal cameras and situational awareness low-resolution cameras. These situational awareness cameras can be used for collision avoidance, whereas the thermal imaging cameras can be used for night vision or heat detection. An embedded processing module can stream all these cameras simultaneously, and record the streams locally while the AI chip tracks and classifies any objects.
Vision AI
Vision AI essentially started with the 2012 ImageNet Large Scale Visual Recognition Challenge (ILSVRC), where the emergence of AlexNet, a convolutional neural network (CNN) architecture, marked a significant leap forward.
This fundamentally changed the challenge of object detection from that of relying on handcrafted feature extraction to one of generating large training datasets and using them to train increasingly sophisticated neural networks.
The success of AlexNet highlighted the scalability and generalisation abilities of deep neural networks and spawned an entire set of AI models.
Increasing focus on efficiency and performance of AI models is expanding this technology for vision-based systems, especially for real-time object classification.

(Image courtesy of DeepX)
At the same time, advancements in image signal processors (ISPs) have improved camera performance using algorithms and what is now referred to as computational imaging (CI).
Modern embedded processors combine central processing unit (CPU), graphics processing unit (GPU) and digital signal processing (DSP) cores with dedicated ISP compute blocks. The open-source community has provided essential tools for creating perception systems, such as the You Only Look Once (YOLO) network, ONNX DNN file formats, frameworks like PyTorch and TensorFlow, and datasets for training and validating models.
Hardware suppliers provide development tools that accelerate the deployment of perception software including tools to convert ONNX format models to the specific compute accelerators on the processors.
(Image courtesy of Teledyne FLIR)
The impact of deep learning on computer vision has led to the development of neural networks for low-cost mobile processors, enabling object detection for video applications like vehicle autonomy. Vision-based products also use SLAM, collision avoidance and object tracking. These computationally intensive tasks are mapped to various System-on-Chip (SoC) subsystems such as GPUs or CPUs, which poses an engineering challenge but saves significantly on power.
Image signal processing and AI object detection algorithms require significant computational resources. For instance, advanced denoising and super-resolution algorithms can perform up to 100,000 operations per pixel per second, which equates to approximately 2 trillion operations per second for a 640 x 512 pixel resolution input at 60 fps, and these typically run on a GPU core. Similarly, large object detection models also demand substantial processing power and typically run on the DSP subsystem or GPU.
There are many variables to consider when developing and deploying an object detector, including the processor architecture, desired accuracy, acceptable latency or frame rate, power budget and thermal impact.
In response to demands to run object detectors on embedded processors, several low-power neural networks have been developed, including YOLO in 2015 and MobileNet in 2017.

YOLO revolutionised object detection with its single-pass approach. Unlike recursive CNNs that involve multiple stages such as region proposals followed by classification, YOLO accomplishes detection and localisation in a single forward pass of the network. The YOLO algorithm offers both speed and accuracy by dividing an input image into a grid, and then predicting multiple bounding boxes and class probabilities simultaneously for each grid cell.
One-stage detectors use a single feed-forward CCN to directly predict object classes and locations. YOLO frames the process of object detection as a regression problem that spatially separates bounding boxes and associates class probabilities. In this way, both object classes and locations can be directly predicted by a CNN. Although two-stage approaches generally produce higher accuracy, the one-stage approach usually operates with higher efficiency.
Quantisation and pruning
The performance of an AI model can be dramatically improved by techniques such as quantisation and pruning.
Quantisation is the compression of floating-point values in neural network parameters to improve model latency when running inference without losing performance. Model training is performed using 32-bit floating-point data and training is done on powerful GPU-based computers designed for this task. Inference on embedded processors can be performed using FP16, FP8, INT8 or INT4 bit depths.
Using INT8 reduces the memory footprint, computational time and energy consumption, and it has been found to be a good compromise between precision and speed in relation to the latest video AI processors.
Regaining computational resources gives developers the flexibility to add more capabilities, including real-time inference on two or more camera feeds.
Pruning is a method used to reduce redundant data in a neural network by determining the importance of each unit and removing unimportant parts. After training, many network neurons have a weight value of zero, and those neurons can be eliminated through a secondary network training process after quantisation.

(Image courtesy of Teledyne FLIR)
Typically, pruning methods include weight pruning, channel pruning and neuron pruning, each of which has specific advantages and disadvantages.
The criteria for determining unit importance can affect accuracy. Constraint learning methods enhance accuracy but their implementation can be complex. Random search pruning is easier but less effective in improving network performance. Method selection should depend on the application, because no single approach synthesises complexity and compression efficiency.
Thermal management
Power consumption is crucial for UAV applications, affecting operating time, logistics and thermal management costs. While FPGA or ASIC processors can minimise power use, third-party analytics and ISP software are usually designed for general purpose CPU cores using frameworks like OpenCV.

For a system running multiple cameras and multiple feature routines like an object detector, target tracker and local contrast enhancement, the developer will reach the upper limit of the throughput of the processor and generate a lot of heat. To help manage this, software developers can incorporate configuration parameters that can be set or adjusted dynamically. For example, in many applications, it is not necessary to perform inference at the frame rate. By reducing the inference output to 10 fps or less, the power profile of the entire software stack might be managed to fit the power budget.
Running CNN models and CI algorithms is extremely computationally demanding. Until recently, embedded processors did not have the power to meet AI and CI workloads. AI requires massive parallelism of multiply–accumulate functions.
For example, one of the latest 4 nm system on chip (SoC) designs features eight CPU cores, two neural co-processors, one GPU, one DSP and a dedicated ISP. The integrated ISP features compute resources for motion-compensated noise reduction, white balance, colour processing, automatic gain control, focus and many other camera functions.
The AI accelerator is suited to running computationally intensive AI workloads. To obtain improved performance and run an AI model on a Hexagon Tensor Processor, the model must be quantised to one of the supported precisions: INT4, INT8, INT16 or FP16.
At the system level, ISP tuning is typically needed to optimise the parameters and various filters to a specific image sensor and lens. Many chip suppliers offer ISP libraries for popular image sensors, potentially saving systems developers significant investment. These include 16- to 8-bit tone mapping (automatic gain control), spatiotemporal denoising, super resolution, turbulence mitigation and electronic image stabilisation. Most of these algorithms run on GPUs given the significant processing demands.
Digital video streams demand considerable memory capacity and bandwidth for efficient signal processing. The SoC executes the largest AI model (input: 768 x 768 pixels) in 6 ms, compared with 33 ms achieved using the previous version, offering over 5x faster inference speed and thereby ensuring frame rate inference for SXGA cameras (resolution: 1280 x 1024 pixels).
Thermal imaging
AI models have been trained using a thermal image data lake containing over 5 million annotations to provide perception software that can detect, classify and track targets or objects for various applications, including automotive autonomy, automatic emergency braking, airborne camera payloads, counter-drone systems, perimeter security and ground intelligence, surveillance and reconnaissance. The image processing involves algorithms for super resolution, image fusion, atmospheric turbulence removal, electronic stabilisation, local-contrast enhancement and noise reduction.

However, there are several issues with thermal imaging on top of the video analysis.
Atmospheric turbulence, resulting from irregular and chaotic motion of fluid or air characterised by velocity, pressure and density fluctuations, impacts photon transmission because of surface-induced solar gain that causes atmospheric mixing. This turbulence churns the air, leading to alterations in the refraction of the infrared signal by substances such as water vapor, smoke and other particulates.
Advanced video processing techniques effectively mitigate distortion effects while preserving high temporal image element quality, thereby ensuring that moving objects are not transformed into indistinguishable shapes or streaks. This capability is crucial for AI-driven target detection, including identifying people and vehicles.
The primary objectives of turbulence mitigation algorithms are to enhance signal quality, reduce noise, and restore clarity and stability under turbulent conditions. The ISP algorithm employs various mathematical and signal processing techniques to analyse and process data affected by turbulence.
A collection of image processing software libraries available for thermal images includes local contrast enhancement, spatial and temporal noise reduction, electronic image stabilisation, turbulence mitigation, super-resolution and several video fusion techniques.
Thermal camera modules typically do not include integrated processors to run the ISP. Therefore, the latest mobile processors can be used in an accessory electronics module to run algorithms at the required video frame rate while meeting acceptable power demands.
The first step is to acquire the data affected by turbulence, which are presented in the form of image frames. The acquired data are pre-processed to remove noise or artifacts that are not directly related to turbulence. This involves using filtering, noise reduction and calibration techniques to improve the signal quality.
(Image courtesy of Tecnologico de Monterrey)
It is then essential to estimate the turbulence characteristics present in the data. This involves analysing the statistical properties of the fluctuations and identifying relevant parameters such as turbulence intensity, correlation length and time scale.
Deconvolution techniques, implemented to reverse the blurring effects caused by turbulence, often utilise mathematical models of turbulence or empirical knowledge to restore the original signal.
Turbulence conditions can vary over time and space and so many turbulence mitigation algorithms employ adaptive filtering techniques. These methods dynamically adjust the filtering parameters based on estimated turbulence parameters to optimise the trade-off between noise reduction and preservation of essential signal features.
After completing the turbulence mitigation steps, additional post-processing might need to be performed to further enhance the quality and reduce artifacts in the final output. Depending on the specific application, this might involve using techniques such as denoising, sharpening, contrast enhancement or feature extraction.
Super resolution
The multi-frame super-resolution method is a technique that aims to reconstruct a high-resolution image from one or more low-resolution images. The optical resolution of a system is limited by the diffraction limit set by the system aperture and the sampling resolution of the detector.
A small aperture and a low-resolution sensor will result in a cheaper and smaller system that will produce poor-quality images with highly aliased or blurred edges. This is especially true when long-range targets are captured using a long focal length optic that scales the effects of diffraction when combined with a finite aperture size.
The super-resolution method reconstructs high-resolution images using data from the degraded inputs. While traditional methods have focused on exploiting the inherent spatial correlations within low-resolution images, recent advancements have used aliasing techniques to improve the results.
There are many different approaches to image fusion or to blending thermal and visible imagery into a single fused video stream. The objective is to extract the unique and valuable information of each spectrum while not requiring the transmission of two or more streams for downstream analysis. This can be complex in practice owing to the need for perfect image registration (alignment) of two or more channels and issues related to the different integration times for each sensor.
Combining video sources
Multi-spectral dynamic imaging uses a high-frequency filter to add sharp details from visible light, such as outlines and text, onto thermal images. This technology is useful in predictive maintenance, security and aerial surveillance.
Automatic gain control enhances the overall visual impact of an image by adjusting the local contrast. Local contrast enhancement improves intricate details, textures and features by expanding the dynamic range within specific regions, unlike global contrast enhancement that alters the contrast uniformly across the entire image.
Monitoring wildfires
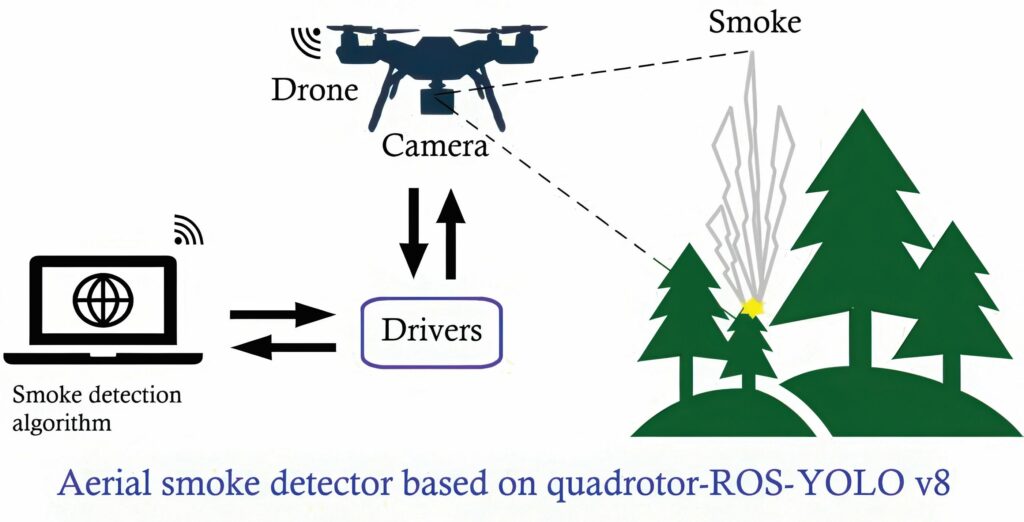
AI can also be used to detect smoke from the air that might indicate the start of a wildfire. Optimising a YOLOv8 nano model allows a standard camera on a UAV to detect smoke with 95% precision and 88.5% recall in detecting early-stage wildfires, even with low computing resources.
Wildfires pose an ever-growing threat to global ecosystems and communities, with climate change exacerbating their frequency and severity. Only 10% to 15% of wildfires occur naturally, such as those ignited by lightning, whereas the remaining 85% to 90% result from human activities, many of which exhibit clear intent like uncontrolled burnings in agriculture.

Obviously, early detection of wildfires is critical to prevent such disasters from escalating. Most existing wildfire detection systems focus on identifying flames and often miss the critical early stages where smoke is the primary indicator.
By detecting smoke before fires escalate, this UAV-based solution offers a timely, scalable and cost-effective method to combat wildfires.
The YOLOv8-based detection algorithm can be deployed in a Robotic Operating System (ROS) framework on a basic Intel Core i5 processor running on a basic laptop. It receives the stream of video at a resolution of 720 x 1020 pixels, a bit rate of 5 Mbps and a frame rate of 30 fps.
One node of the ROS is used for continuous information exchange with the drone, a second node is used to issue flight instructions, and a third node executes YOLOv8 model inference on the received images. The second node also provides the predefined mission data.
Through tuning the AI parameters in the OpenVINO AI framework, the model achieves robust detection on video with standard resolution without sacrificing speed.
The system underwent validation both in laboratory settings utilising controlled smoke images and in field experiments involving real smoke, dynamic lighting and environmental interference. It addressed traditional detection biases through comprehensive testing and dataset augmentation, which encompassed over 2000 labelled images representing various smoke conditions. These conditions included factors such as blurriness, brightness, luminosity, cloud and mist exclusion, and video channel interference.
(Image courtesy of NTT research)
The system can be deployed in forests, mountains and other inaccessible regions, offering a rapid response to emerging fire threats.
The camera is mounted on a quad core UAV and is being integrated with automated fire suppression mechanisms, enabling wildfire management from the air. Future implementations could include fleets of UAVs using the video systems to collaboratively monitor larger areas and assist in real-time firefighting operations.
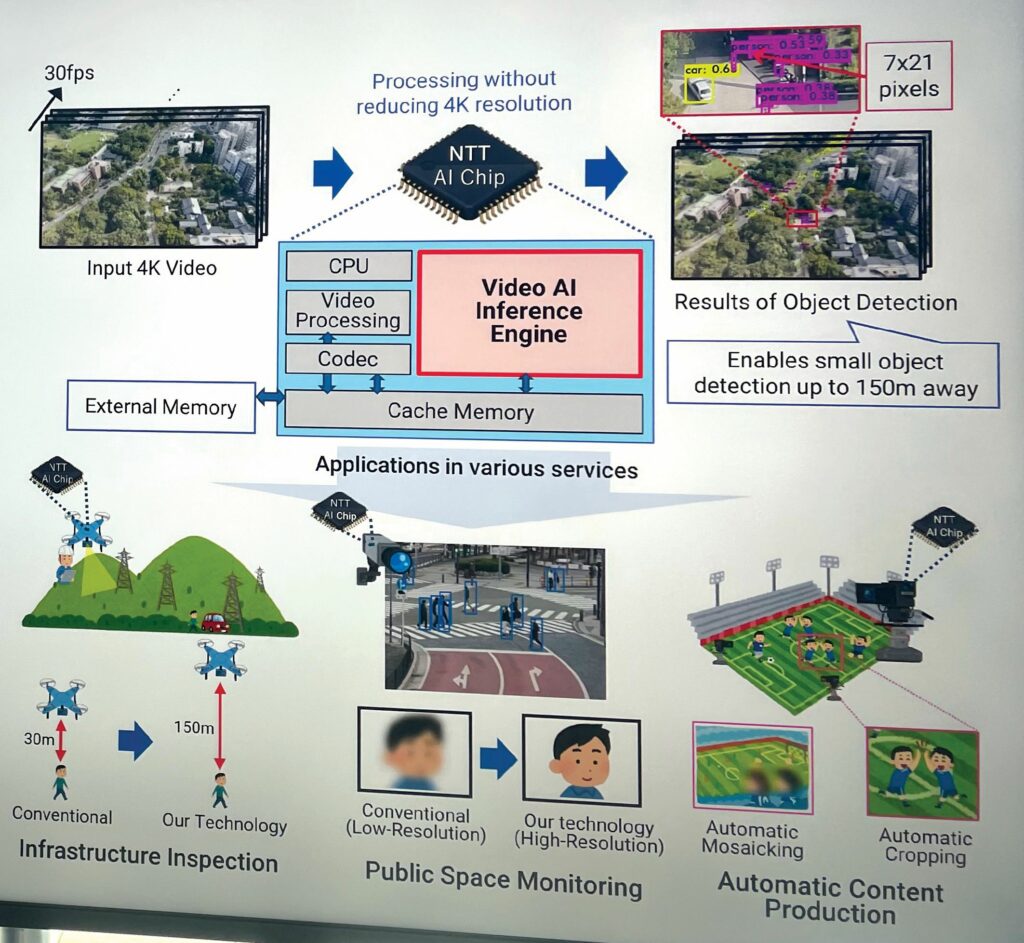
4K AI analysis
AI has been used in an inference chip for real-time processing of ultra-high-definition video on edge devices such as UAVs. This allows the UAV to detect individuals or objects from up to
492 feet (150 m) above the ground, the legal maximum altitude of drone flight in a country such as Japan, whereas conventional real-time AI video inferencing technology would limit that drone’s operations to about 98 feet (30 m).
Transformers
The next generation of embedded AI processors combine compute arrays capable of handling transformer AI models. These are used for generative AI such as Large Language Models (LLMs) but there are video processing algorithms being trained on these models that could provide higher performance with more power efficiency, albeit with higher overall power consumption.
These AI processors combine up to 16 camera channels with the AI array for self-driving vehicles. This allows a single chip to handle the feeds from multiple cameras around the vehicle but also to include voice control for passengers via the LLM.
Acknowledgements
With thanks to Arthur Stout and Kedar Madineni at Teledyne FLIR, Les Letwin at Antrica and Jesus Gonzalez-Alayon and Herman Castañeda at the Tecnologico de Monterrey, School of Sciences and Engineering, Monterrey, Mexico.
UPCOMING EVENTS



